Groq 如何用14nm的LPU
打敗了4nm的NVIDIA H100呢?


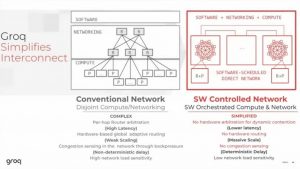

我認為有幾個設計亮點
1) 採用Dataflow架構
↪︎Dataflow架構會使用編譯器預先做好排程,可降低控制電路面積
↪︎目的:最大化晶片的算力與SRAM記憶體大小
2) 捨棄傳統多階層的Memory Hierarchy
↪︎不使用DRAM/HBM,也不將SRAM記憶體編排成L1、L2、L3 cache等階層,只有一層軟體可控的SRAM記憶體 Scratchpad
↪︎目的:SRAM可以直接供給運算單元資料,最大化記憶體頻寬 (80 TBps)
3) 捨棄複雜的跨晶片Networking
↪︎讓LPU也成為Router,使用Compiler來控制跨晶片的資料傳輸
↪︎目的:簡化晶片之間傳輸資料所需要的硬體成本,可彈性配置跨晶片頻寬、提升頻寬利用率
▌參考資料
[1] Groq Head of Silicon-Igor Arsovski的演講:https://youtu.be/WQDMKTEgQnY?si=Bicqpg2yPM3jvXZ6
[2] Groq Chief Architect在Stanford的演講:https://youtu.be/kPUxl00xys4?si=sV8r_MrX7GLN7ZLV
[3] Think Fast: A Tensor Streaming Processor (TSP) for Accelerating Deep Learning Workloads, ISCA’20 (計算機結構四大頂尖會議)
[4] A software-defined tensor streaming multiprocessor for large-scale machine learning, ISCA’22
[5] The J-Machine Multicomputer: An Architectural Evaluation, ISCA’93
註:基本上台灣10年只會有5篇以內的計算機結構頂會,難度超高
i.e., ISCA、MICRO、HPCA、ASPLOS